- What is credence?
- What is credence calibration?
- How does the credence calibration game work?
- How are the questions generated?
- Why are the questions so hard?
- Why this scoring rule?
- What do the scores mean?
- Wait, what is information anyway?
- Is my score affected by my level of knowledge?
- What about other scoring rules?
- Reality does not run on subjective probabilities! What’s the point of calibrating them?
In spring 2012, as a project for the Center for Applied Rationality (CFAR), Alexei Andreev, Zachary Alethia and I created this simple game for training people to adjust their reported credence levels to more closely reflect their success rates on answering questions. It’s a very crude implementation of the concept, but has been used in CFAR’s workshops on rationality, and by Professors Saul Perlmutter, John Campbell and Robert MacCoun in their course, “Sense, Sensibility, and Science.” If you’d like to develop an update to the game, please contact me!
What is credence?
Credence is a measure of belief strength in percentage. Roughly, you’re at least 90% credent that Joe is at the party if you’d rather bet that Joe is at the party than bet on a roulette wheel with 89% of its slots marked “win”.
If this idea is new to you, you can still play the credence calibration game! You can also read this lengthier discussion of what credence is.
What is credence calibration?
If Joe is only right 60% of time when he says he’s 90% sure, Joe is said to be overconfident. As it turns out, most people are overconfident in this way: their success rates at making correct predictions are much less than how sure they report to be, in percentages. Let’s fix that!
We say Joe is well calibrated if he’s right X% of the time when he says he’s X% sure, or very near to that, for all X. Being well-calibrated is cool, because it means you’re able to tell people something predictable and accurate about how much to trust you. It can even be seen as a kind of honesty: if you act like you know something, but you don’t, it can mislead people, and calibration can help you avoid doing that either accidentally or unconsciously.
(Even if you sometimes want to signal or feel overconfidence, it’s nice to at least have the ability to report honest and well-calibrated credences to yourself and others; the game is meant to help with that.)
How does the credence calibration game work?
The credence calibration game has a built-in tutorial to teach you how to play, and is meant to help you do two things:
- Practice the mental action of converting your internal sense of “sureness” into a credence level that you can report to yourself and others, and
- Train over time so that your credence levels more closely reflect your success rates.
In the game, you answer two-choice questions and give %-credence values with your answers, and the game awards you points according to the following very carefully chosen scoring rule:
| Player-reported credence | 50% | 60% | 70% | 80% | 90% | 99% |
| Score if correct | 0 | +26 | +49 | +68 | +85 | +99 |
| Score if incorrect | 0 | -32 | -74 | -132 | -232 | -564 |
Your goal while playing is to maximize the number of points you get, and the game gives you feedback on whether you are over- or under- confident with your various reported credences. See below for more discussion of the scoring rule.
How are the questions generated?
We generate each question from a database of lists. For example, using a list of rich people and their net worths, we can generate many questions of the form “Who is richer, A or B?”
We wanted to avoid choosing the answers for the questions ourselves because we might be biased in some way, e.g. to make them tricky, like many trivia games are. While playing we want people to think as much as possible about their knowledge of facts rather than our psychology. (It could also be cool and valuable to make a psychology-guessing game, but we didn’t go for that.)
When a question asks, e.g., “Who is richer?”, and the names are drawn from a list of rich people, we try to say that as part of the question so that the user doesn’t think, “Oh, Bill Gates, I know he’s super rich so I’m 90% sure he’s richer than this other person I haven’t heard of.” The question would read “Each of these people was among the 10 richest in the world by personal assets in 2011; who was richer?”
We also used lists because we wanted to use two-choice questions instead of true-false questions. Most random statements one can make about the world are false (e.g. <insert name here> was born in <insert country here>), so using a database of questions where half of them have “true” as the response might train an unnatural bias for thinking statements are true. On the other hand, when deciding “which of these things is bigger?” in real life, it’s natural to have a 50/50 opinion until you think about it or remember something.
Why are the questions so hard?
We chose a variety of question topics such that many people on some topics feel like they have “no idea”. E.g., many of our users feel like they have “no idea” about sports questions, and feel like they have to click 50%. But cross-domain inference is totally cool and worth training! It turns out that you can sometimes use your knowledge from other domains (geography, history, etc.) on such questions to get the answer right 60% or 70% of the time. We don’t want to spoil the fun, so try figuring out your strategies for that. If it turns out you just don’t know enough related knowledge to guess at sports questions, at least you’ll know that having tried, and you’ll be better calibrated about it 🙂Why this scoring rule?
The scoring rule is mainly chosen to elicit honesty and motivate calibration from the user. In short, with this scoring the system, the best strategy at any moment is to honestly report your credence level, and over time, adjusting your credence levels to more accurately reflect your success rates will actually improve your score. That is, just like in real life, calibration is not the goal of the game… it’s part of the winning strategy.
This is actually quite a subtle property for the game to satisfy! If calibration were the only goal, the user could simply flip a coin to choose between A and B every time, and will end up being perfectly calibrated. The challenge in the game — and in life — is for your credences to be informative to yourself and others.
In particular, since the best strategy is to honestly report your credence, you must expect positive score for reporting! Indeed, average the score you (subjectively!) expect to receive for answers with particular credences are as follows:
| Player-reported credence | 50% | 60% | 70% | 80% | 90% | 99% |
| Player-expected score | 0 | 3 | 12 | 28 | 53 | 92 |
What do the scores mean?
Your score measures how informative your credences are. More specifically, your score on a question is the number of centibits — hundreths of a bit of information about the answer — that your response would provide as a belief update to someone who is 50% sure of each answer.
For example, say you answer with a credence of 80%. If you’re correct, you get 68 points because the probability you assigned to the truth was
-
80%=20.68(50%)
-
20%=2–1.32(50%)
Wait, what is information anyway?
If you’re new to information theory, please read this intuitive discussion of information scoring… it’s cool!Is my score affected by my level of knowledge?
Yes, just like in real life: how informative you are to others is affected by your level of knowledge. But your calibration also affects your score, just like in real life: being well-calibrated helps you to better inform people of your knowledge level (or lack thereof).
The point is that, for a given level of knowledge, you can improve your score — how informative you are ‐ by giving better calibrated responses. For example, say you know a lot about geography questions, such that your actual success rate on them is 70%. On average, you can still get points for saying you’re 60% or 80% sure, but not as many points on average as you’d get if you said 70% sure. And if you’re right 70% of the time but saying you’re 90% sure, you’d actually get negative points on average. Your average pay-off for the various responses, assuming a 70% success rate, looks like this:
| Reported credence | 50% | 60% | 70% | 80% | 90% | 99% |
| Average score with 70% success rate | 0 | 9 | 12 | 8 | -10 | -100 |
Notice the best strategy is to just say 70%… which is what we want! This works out for all the other success rates, too.
What about some other scoring rules?
Let’s consider some examples. If we use the following scoring rule| Player-reported credence | 50% | 60% | 70% | 80% | 90% | 99% |
| Score if correct | 0 | +10 | +20 | +30 | +40 | +49 |
| Score if incorrect | 0 | -10 | -20 | -30 | -40 | -49 |
it turns out that the best strategy is to always say 99% for whichever answer you think is slightly more likely… this definitely doesn’t lead to calibration! If we use
| Player-reported credence | 50% | 60% | 70% | 80% | 90% | 99% |
| Score if correct | 0 | +10 | +20 | +30 | +40 | +49 |
| Score if incorrect | 0 | -20 | -40 | -60 | -80 | -98 |
the best strategy is to be very slightly dishonest on each answer and very slightly miscalibrated over time.
There are other scoring rules which elicit honesty and calibration which are not simple transformations of our relative information rule. For example, 2500-(mean squared error) also works:
| Player-reported credence | 50% | 60% | 70% | 80% | 90% | 99% |
| Score if correct | 0 | +900 | +1600 | +2100 | +2400 | +2499 |
| Score if incorrect | 0 | -1100 | -2400 | -3900 | -5600 | -7301 |
But this formula doesn’t have the intuitive meaning of informativity that our rule has, and it wouldn’t penalize a credence of 99.999% on wrong answers enough to strongly dissuade unjustified absolute certainties.
Another possibility for scoring would be to actually have the player choosing between bets in some way, explicitly or implicitly, as in the definition of credence, and award points based on randomized bet outcomes. But this would add an extra source of variance to the player’s score (in addition to that already present from having a finite sample from their distribution of all possible responses to questions). We thought this would make learning more difficult, but we’re not 99% sure of that! If you’d like to work on an implemetation based directly on betting preferences, please email me — critch@math.berkeley.edu — and I can share some ideas about this over a phone or Skype conversation.
Reality does not run on subjective probabilities! What’s the point of calibrating them?
For those asking this question from the school of frequentist statistics, it’s worth noting that calibration is actually a very frequentist notion: it is meant to bridge the gap between the purely subjective definition of credence and the objective frequency of success rates.
The most common objection to using probabilities to represent strength of belief in a prediction is that probabilities should represent frequencies among repeated events, and some predictions will never be repeated. For example, Obama will only run for election in 2012 once… what sense would it make to give a % probability of him winning? Either he will win, or he won’t!
First of all, the standard definition of credence is in terms of betting preferences, not in terms of frequency of events. Being 70% credent Obama will win roughly means being indifferent between betting on Obama and betting on a 70%-biased roulette wheel.
Okay, but what then does it mean for that 70% to be well-calibrated? The point is that there is no real meaning of calibration on a single event, for exactly the reason that there is no objectively correct probability to assign to Obama winning in 2012, unless you mean 100% (in retrospect, he did win). Calibration is a property of your series of reported credences over time, not a single report.
Okay, but so what if I’ve been well-calibrated on a bunch of past predictions? Is there any reason to pay more attention to my credence on my next prediction? Even though it’s not a repetition of any of my past predictions?
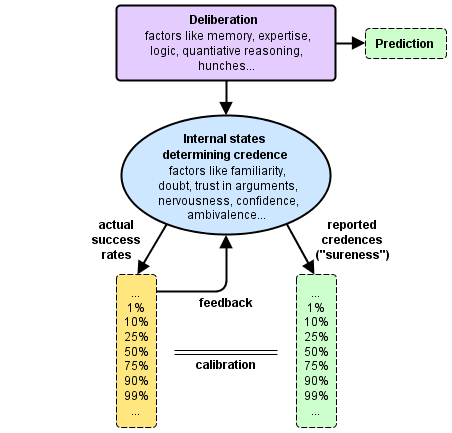
In fact, yes there is! The reason is that, although our past predictions are perhaps not being repeated, our internal proxies for credence — internal emotional and heuristic cues of how much to trust ourselves — are highly repetitive in comparison to the variety of events happening in the external world.
In other words, there is something in common among all situations in which we make predictions: our own psychology. For this reason, there is some hope that calibration practice on one domain of questions could lead to somewhat better calibration in other domains. (Please contact me if you’re a social scientist wishing to run this experiment!)
The real idea behind the credence calibration game is not just to calibrate our utterances of the number “70%”, but our conversion of our internal proxies for credence into numbers. For example, maybe when we say 70% and feel nervous, we’re right 80% of the time, and when we say 70% and feel relaxed, we’re right 40% of the time! That would be interesting to note, and future versions of the game might have some optional emotion buttons to click on (though we don’t want to choose the emotion buttons arbitrarily, because we don’t want to bias people to pay undue attention to the wrong emotions). Having only the number to click on is our first approximation to this finer calibration practice.
In any case, our cartoon picture of how calibration practice works over time is summarized in the following diagram: